The 2026 World Cup Happens Outside the Stadium Walls
Insights
| 11 Jun 2026
Key Takeaways
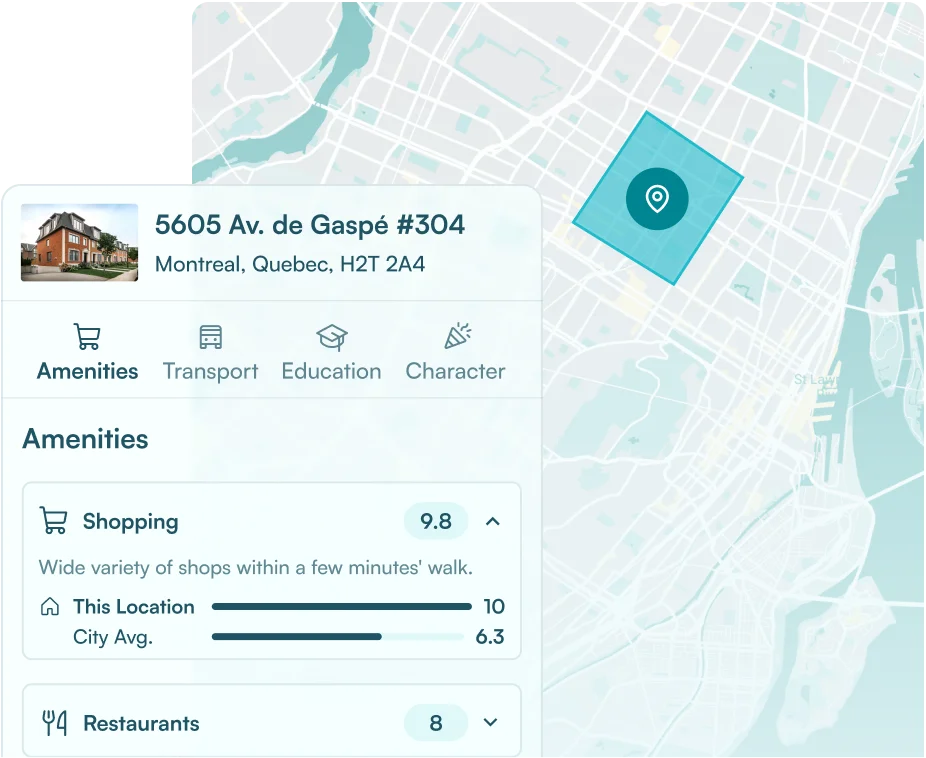
Most location data was built to be read, not computed. It was designed to answer a question a person would ask, such as what’s the walkability here, what amenities are nearby, what does this neighborhood look like, and then display the answer on a screen. That use case still exists. But it’s no longer the only one that matters.
The question CRE platform and data teams are asking about location intelligence has quietly shifted, going from “What does this show a user?” to “What does this help our model decide?” That changes what the data needs to look like, how it has to be structured, and what it actually means to choose the right location data partner.
If you’re building a CRE platform that touches automated valuation, deal screening, site selection, or any kind of neighborhood-aware prediction, which data layer you decide to implement now will shape what your models can actually do.
Location intelligence has always added value at the display layer by enriching property pages, populating community portals, and giving users the neighborhood context they need to make confident decisions. That use case isn’t going anywhere. However, a second, complementary way in which most forward-thinking CRE platforms are applying that same data is as a structured input that algorithms use to produce outputs
The two use cases aren’t in competition, but they do ask something different of the data. A walkability score that communicates clearly to a human reader on a property page also needs to be normalized consistently across all markets in the dataset when used as a weighted factor in a valuation model. It needs to mean the same thing whether an asset sits in a dense urban core or a suburban ring, and it needs to be stable enough that the model team can reason about what it represents across different geographies and time periods.
When location data is built to support both use cases, the model has a reliable, interpretable signal to work with from the start. Location intelligence then strengthens the output instead of introducing noise that’s difficult to trace back later.
💡 AI models are only as good as the underlying data and features they are trained or prompted on. Proprietary, normalized, and explainable location signals don’t just improve model performance; they become a defensible competitive moat for the platforms that use them.
For teams building inference applications on top of location intelligence, it’s worth being precise about what model-ready actually means in practice. For location data to function reliably as a model input, three properties matter most:
Location signals function best as model features when they mean the same thing regardless of geography. A score normalized consistently across dense urban environments and suburban markets gives the model a signal it can reason about clearly, distinguishing a genuine difference in location quality from a difference in how markets are structured. That consistency is what makes cross-market models stable, generalizable, and trustworthy in production. For platforms operating across multiple metros, this is the foundational property. Everything else in the model builds on it.
CRE analysis rarely maps neatly to standard administrative boundaries. Trade areas for retail site selection are defined by drive times and pedestrian catchment zones. Multifamily catchment areas follow employment corridors and transit lines. Industrial site analysis might center on highway access radii.
Location data that supports custom polygon queries (i.e., trade areas and catchment zones defined by the platform rather than inherited from census geography) gives model teams the ability to aggregate signals around boundaries that reflect actual market dynamics. That’s a meaningful capability for platforms where the geographic unit of analysis is core to the product.
Valuation models and deal prioritization tools that depend on location signals benefit from data that reflects current conditions. Frequent refresh cycles give model teams confidence in the currency of the signal, which is particularly important for AI valuation tools where neighborhood context is part of the output, and where data freshness directly affects result quality. For production applications with real capital decisions behind them, freshness is a meaningful part of the overall data quality story.
The applications below reflect where sophisticated CRE platform teams are already using location intelligence as a model input. Instead of content displayed to end users, location data is used as structured signals that algorithms consume to produce outputs.
Investment platforms are embedding location signals as weighted factors inside proprietary scoring models (alongside transaction data, cap rates, and historical comps) to produce valuations that account for neighborhood quality rather than just financial fundamentals. In this use case, walkability scores, transit access, amenity density, and demographic profiles never appear on a screen. The model consumes them and adjusts its estimates accordingly.
The quality of these valuations depends directly on the consistency and granularity of the location signal. A model trained on well-normalized, cross-market location data generalizes more reliably to new geographies, which matters for platforms with national or multi-market ambitions.
Before full underwriting is warranted, investment teams use location intelligence to filter a broad universe of acquisition candidates. Which assets have the neighborhood profile that fits the investment thesis? Which locations score well on the factors (e.g., transit access, employment density, school quality, retail concentration) that correlate with leasing performance for a given asset category?
Querying Location Scores and demographic signals by address, aggregated across custom portfolio geographies, turns this into a repeatable, systematic analysis rather than a manual research task. The value isn’t any single data point. Instead, it’s the ability to apply a consistent location quality screen across thousands of candidates before the first site visit.
Geographic flexibility is the other piece. CRE analysis rarely maps to census tracts or zip codes. Trade areas follow drive times and pedestrian catchment zones. Catchment areas follow employment corridors and transit lines. Data that supports custom polygon queries (i.e., boundaries defined by the platform rather than inherited from census geography) lets model teams aggregate signals around boundaries that reflect actual market dynamics.
The data layer decision for AI-native CRE products is best made before model training begins. Normalization conventions, schema definitions, and geography abstractions get encoded into model weights during training, which means the quality of those choices compounds over time as the model develops and improves.
Platforms that invest in consistent, normalized, frequently refreshed location data early in the development cycle find that the foundation pays dividends throughout the model’s lifecycle in generalization across markets, in interpretability, and in the confidence the team has in what the model is actually learning.
💡 The data architecture decision isn’t just a vendor evaluation. It’s a modeling decision whose impact grows the further into development you go.
The expansion of location intelligence from display enrichment into model input is already underway across CRE in automated valuation, deal screening, site selection, and neighborhood-aware AI tools. The platforms building in this space are learning that the data infrastructure decisions made early in development have a long reach.
Location data that is consistent across markets, flexible across geographies, and refreshed frequently gives CRE models a reliable foundation to build on. Those three properties, more than any single feature or data point, are what determine how much analytical leverage location intelligence can add to a CRE platform over time.
Local Logic’s location intelligence APIs, including Location Scores and Demographics, are built for machine consumption. Our data is normalized across markets, queryable by custom polygon, and updated frequently. To explore how they fit into your data architecture, reach out to the Local Logic team.
➡️ Book a meeting with Max Leblond (VP of Marketing) and Josh Partridge (Director of Strategic Partnerships) at ICSC + PROPTECH 2026 to explore how Local Logic’s location intelligence suite supports CRE model applications, from automated valuation to trade area analysis.