The 2026 World Cup Happens Outside the Stadium Walls
Insights
| 11 Jun 2026
Real estate has always been a business where accuracy matters. Wrong school catchment data costs a family a school place. A stale Quiet score sends a buyer to a street that sounds nothing like the listing promised. An outdated market stat makes an agent look unprepared in front of a seller. AI doesn’t change that. It just makes the cost of getting it wrong much higher.
As AI-powered search, automated content, and intelligent recommendation engines become standard in real estate products, every inaccuracy in the underlying data gets surfaced faster, at greater scale, and in front of more people. The tolerance for “close enough” is shrinking, not growing. It’s not only about whether AI is a threat or an opportunity, but what it takes for a real estate data API to actually be useful. The answer, in every case, is the same: accurate, structured, and regularly updated location data.
Because AI makes errors faster and at a greater scale. A plausible-sounding but inaccurate output gets surfaced to more users, more quickly, and with more apparent confidence than a human making the same mistake.
AI is genuinely good at generating fluent, confident-sounding text. That’s also what makes data quality so important. A language model describing a neighborhood from its training data produces something that reads well, but “reads well” and “is accurate” are not the same thing.
Take, for example, a Quiet score that doesn’t reflect proximity to an actual noise source, a median price that’s six months stale, or a school listed in the wrong catchment zone. Those are the kinds of errors AI scales rapidly when the data feeding it isn’t right.
In real estate, consumers and agents catch these errors quickly. And when they do, the platform that surfaced the inaccuracy, not the AI tool, takes the reputational hit.
To produce reliable results, AI models in real estate need structured, validated, and regularly updated location data that cannot be derived from training data alone. That means proprietary scoring models, normalized geographies, daily-updated market statistics, and school catchment data tied to real addresses.
Here’s what no AI model can produce from training data alone:
These require structured, validated, and regularly maintained data pipelines. The gap between “plausible” and “accurate” is exactly where real estate decisions get made, and where AI tools either earn trust or lose it.
The real estate platforms getting AI right are the ones that treat data quality as the foundation, not an afterthought. Here’s where that shows up most clearly:
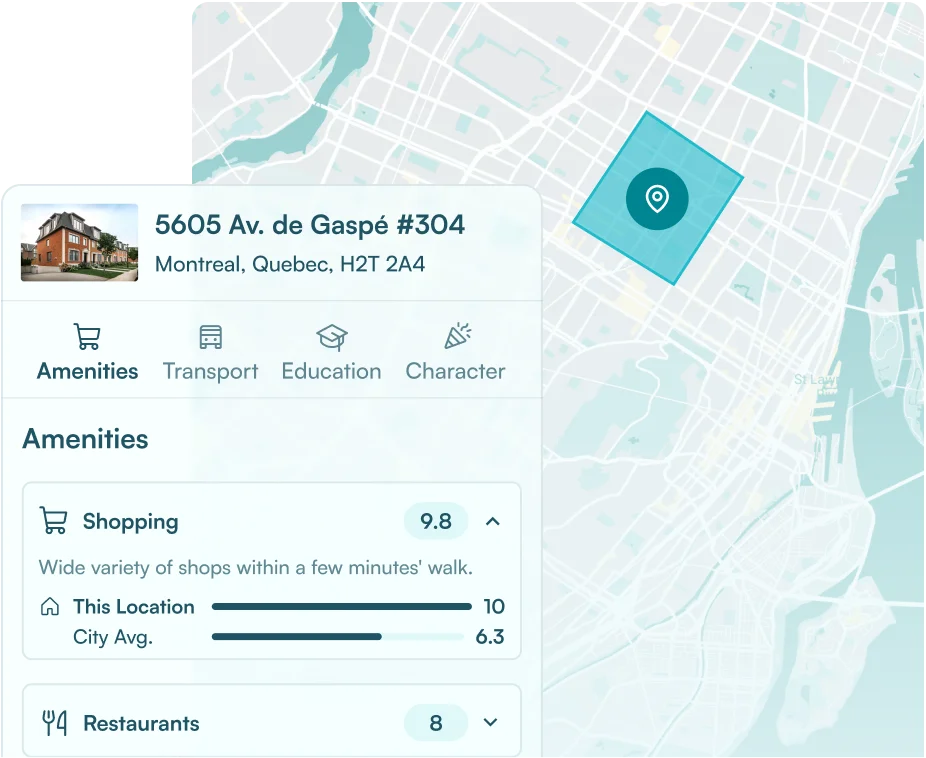
When a buyer types “I want something quiet, walkable, near good schools,” a search interface that actually delivers on that needs structured, queryable signals for each attribute: a Quiet score, a Walkability score, school proximity, and catchment data. Without those signals, the AI is pattern-matching on text, not ranking based on real data. The interface looks intelligent, but the results aren’t.
Input data: Local Logic’s suite of APIs, such as Location Scores API and Schools API, are all structured, schema-consistent, and queryable the same way, and makes this kind of search accurate rather than just plausible.
A valuation model is only as current as the market data feeding it. Stale inputs produce stale outputs, and in a market where consumers and agents can immediately cross-reference a number, that’s a fast way to lose credibility.
Input data: Local Logic’s Market Stats API delivers regularly updated sold data and market trends that valuation models can rely on.
Platforms generating neighborhood descriptions at scale using AI need a ground-truth data layer to keep that content accurate. The AI writes the words; the data determines whether those words are true.
Input data: Local Logic’s Local Profiles API provides structured, normalized neighborhood data across hundreds of thousands of geographies, helping you build a solid foundation for generating reliable AI content.
“Similar neighborhoods” carousels, lookalike suggestions, and personalized discovery features need normalized, comparable location metrics to work accurately. The logic that powers those features (i.e., “if you like this neighborhood, you’ll probably like these”) only holds up when the underlying scores are consistent, comparable, and current. For accurate recommendations, you need more than just loose proximity; you need structured data.
AI will replace inaccurate, generic neighborhood content. It won’t replace content that’s specific, accurate, and grounded in real data since that’s exactly what AI search engines look for when deciding what to cite.
Brokerage websites with thin, static, surface-level neighborhood pages are already losing ground. That’s not because AI is writing better versions of the same generic content, but because buyers are now getting direct answers from AI search tools instead of clicking through to a page that says less.
The websites that hold their position are the ones powered by data that can’t be replicated from a training set, like Quiet scores that reflect what that specific block actually sounds like, market stats from last week, or school catchment zones accurate for the current enrollment year. That’s the content AI search surfaces and cites. Accuracy is what separates pages that get cited from pages that disappear.
For most product teams, buying is the better option, not just for speed, but for data quality. Maintaining the accuracy, freshness, and normalization that AI features require is a continuous operational commitment, not a one-time build.
Assembling a neighborhood data API stack from scratch (geographies, scores, market stats, points of interest, demographics, school catchments) involves ongoing validation, source reconciliation, and pipeline maintenance. Most product teams underestimate how much of that work is continuous rather than fixed. For AI-native features, where stale or inconsistent data directly degrades output quality, “good enough at launch” isn’t good enough.
A product that pulls location intelligence from one clean, well-documented API (instead of four separate suppliers with four different schemas and four different refresh cadences) is easier to maintain, faster to ship on, and more reliable to train models on. When accuracy is the foundation your AI features stand on, it’s a product quality decision.
AI raises the stakes for data quality instead of lowering them. Every AI-native feature in a real estate product, whether it’s search, recommendations, content, or valuation, inherits the accuracy of the data underneath it. Get the data right, and AI becomes a genuine multiplier. Get it wrong, and AI scales the inaccuracy.
The platforms that will win in an AI-native real estate market aren’t necessarily the ones with the most sophisticated models. They’re the ones whose models are built on data that’s accurate, structured, normalized, and current.
Real estate was always built on accuracy. AI just makes the cost of getting it wrong much higher.
Curious how Local Logic’s APIs can fit into your AI-native product or platform?
➡️ Book a meeting to get a personalized demo